Virtualization with SAP HANA
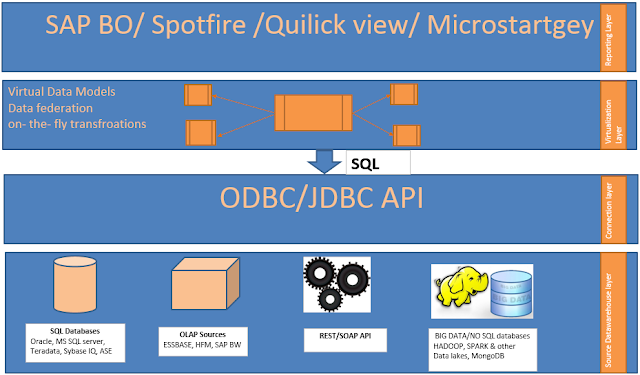
Virtualization Most of Corporate Enterprise warehouse Eco system consists multiple disparate Data warehouses. reason can be attributed to mergers and acquisitions, departments using specialized software, databases choose to support specific data needs. All these scenarios result in building multiple data marts over multiple technologies. However, to serve the purpose of single source of truth, we end up building Enterprise Data Warehouse(EDW) by sourcing data from various data marts across organization. One way of doing is, running a project for establishing standard ETL methods to extract data from regional Data Marts and staging data into EDW. However various departmental/ regional DW already contains highly formatted, information rich and aggregated data built readily available. This implies that we might not need to 1. Perform extensive transformations 2. Source data is meta data rich 3. Less data volumes will be retrieved from source systems Following trad...


